Blackfin プロセッサは、Analog Devices と Intel を通じて Micro Signal Architecture (MSA) として設計、開発、販売されました。このプロセッサのアーキテクチャは 2000 年 12 月に発表され、最初に ESC ( 組み込みシステム この Blackfin プロセッサは主に、現在の組み込みオーディオ、ビデオ、および通信アプリケーションの消費電力の制約と計算上の要求に対応するように設計されています。この記事では、 Blackfin プロセッサ – アーキテクチャとそのアプリケーション。
Blackfin プロセッサとは?
Blackfin プロセッサは 16 ビットまたは 32 ビットです。 マイクロプロセッサ これには、16 ビット MAC (積和演算) を介して提供される固定小数点 DSP 機能が組み込まれています。これらは プロセッサ 主に、リアルタイムの H.264 ビデオ エンコーディングのような困難な数値タスクを同時に処理しながら、OS を実行できる結合された低電力プロセッサ アーキテクチャ用に設計されました。
このプロセッサは、汎用マイクロコントローラ内にある属性を簡単に使用して、32 ビット RISC とデュアル 16 ビット MAC 信号処理機能を組み合わせています。したがって、この処理属性の組み合わせにより、Blackfin プロセッサは、制御処理と信号処理の両方のアプリケーションで同様の成果を上げることができます。この機能により、ハードウェアおよびソフトウェア設計の両方の実装タスクが大幅に簡素化されます。

ヒラスズキの特徴:
- このプロセッサは、単一の命令セット アーキテクチャを備えており、その処理性能は、 デジタル信号プロセッサ または DSP を使用して、コスト、電力、およびメモリ効率を向上させます。
- この 16 または 32 ビット アーキテクチャ プロセッサは、今後の組み込みアプリケーションを単純に可能にします。
シングルコア内でのマルチメディア、信号および制御処理。 - 開発者の生産性を向上させます。
- 電力消費または信号処理のための動的電力管理を通じて、調整可能なパフォーマンスを備えています。
- これは、さまざまな設計に非常に迅速に採用され、いくつかのツールチェーンとオペレーティング システムによって簡単にサポートされます。
- 強力なソフトウェアの開発環境とコア パフォーマンスが組み合わされているため、最小限の最適化が必要です。
- Blackfin プロセッサは、業界をリードする開発ツールをサポートしています。
- このプロセッサのパフォーマンスと競合する DSP の半分のパワーにより、高度な仕様と新しいアプリケーションが可能になります。
Blackfin プロセッサのアーキテクチャ
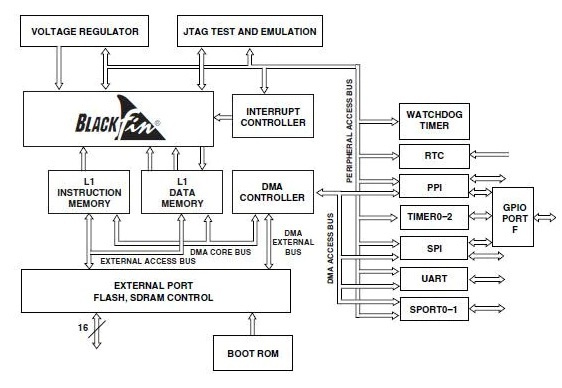
Blackfin プロセッサは、マイクロコントローラ ユニットの機能と デジタル信号処理 柔軟性を可能にすることにより、単一のプロセッサ内で。したがって、このプロセッサには、可変長のようないくつかの機能を含む SIMD (単一命令複数データ) プロセッサが含まれています。 危険 命令、ウォッチドッグ タイマー、オンチップ PLL、メモリ管理ユニット、リアルタイム クロック、100 Mbps のシリアル ポート、 UART コントローラー& SPI ポート。
MMU は複数の DMA ペリフェラルと FLASH、SDRAM、および SRAM メモリ サブシステム間でデータを転送するチャネル。また、データキャッシュと構成可能なオンチップ命令もサポートしています。 Blackfin プロセッサは、8、16、および 32 ビットの算術演算をサポートする単純なハードウェアです。
“電気部品とその用途 ”
Blackfin アーキテクチャは、主にマイクロ信号のアーキテクチャに基づいており、ADI (アナログ デバイス) と Intel が共同で開発したもので、32 ビット RISC 命令セットと、デュアル 16 ビット積和演算を備えた 8 ビット ビデオ命令セットが含まれています。 (MAC) 単位。

アナログ デバイスは、Blackfin の命令セット アーキテクチャを通じて、DSP と MCU の要件のバランスを取ることができます。通常、Blackfin プロセッサは強力な VisualDSP++ ソフトウェア開発ツールと結合されていますが、C または C++ を使用することで、効率の高いコードを以前よりも非常に簡単に作成できるようになりました。リアルタイム要件については、オペレーティング システムのサポートが重要になるため、Blackfin はサポートしていません。オペレーティングシステムとメモリ保護の。 Blackfin プロセッサには、BF533、BF535、BF537 のようなシングルコア モデルと、BF561 モデルのようなデュアルコア モデルの両方があります。
Blackfin プロセッサ アーキテクチャには、PPI (パラレル ペリフェラル インターフェイス)、SPORTS (シリアル ポート)、SPI (シリアル ペリフェラル インターフェイス)、UART (ユニバーサル非同期レシーバ トランスミッタ)、汎用タイマ、RTC (リアルタイムクロック)、ウォッチドッグ タイマー、汎用 I/O (プログラマブル フラグ)、 コントローラ エリア ネットワーク (CAN) インターフェイス 、 イーサネット MAC、ペリフェラル DMA -12、ハンドシェイク DMA、TWI (Two-Wire Interface) コントローラ、デバッグまたは JTAG 32 のインターフェイスとイベント ハンドラー 割り込み 入力。アーキテクチャ内のこれらすべてのペリフェラルは、さまざまな高帯域幅バスを介してコアに簡単に接続されます。そのため、これらの周辺機器のいくつかについて以下に説明します。
PPI またはパラレル ペリフェラル インターフェイス
Blackfin プロセッサは、パラレル ペリフェラル インターフェイスとしても知られる PPI を提供するだけです。このインターフェイスは、パラレル アナログ - デジタル & デジタル - アナログ コンバーター、ビデオ エンコーダー、デコーダー、およびその他の汎用周辺機器に直接接続されます。
このインターフェイスには、専用の入力 CLK ピン、3 つのフレーム同期ピン、および 16 のデータ ピンが含まれます。ここでは、入力 CLK ピンは、システム CLK 速度の半分に等しいパラレル データ レートをサポートするだけです。 3 つの異なる ITU-R 656 モードは、アクティブ ビデオ、垂直ブランキング、完全なフィールドのみをサポートします。
PPI の汎用モードは、さまざまな伝送およびデータ キャプチャ アプリケーションに適合するように用意されています。したがって、これらのモードは、内部生成フレーム同期によるデータ受信、内部生成フレーム同期によるデータ送信、外部生成フレーム同期によるデータ送信、および外部生成フレーム同期によるデータ受信の主なカテゴリに分けられます。
スポーツ
Blackfin プロセッサには、シリアルおよびマルチプロセッサ通信に使用される 2 つのデュアルチャネル同期シリアル ポート SPORT0 および SPORT1 が含まれています。したがって、これらはサポートする高速で同期のシリアル ポートです。 I²S 、TDM、および接続用のその他のさまざまな設定可能なフレーミング モード DAC 、ADC、 FPGA およびその他のプロセッサ。
SPI またはシリアル ペリフェラル インターフェイス ポート
Blackfin プロセッサには、プロセッサがさまざまな SPI 互換デバイスと通信できるようにする SPI ポートが含まれています。このインターフェイスは、データを送信するために 3 つのピン (データ ピン 2 と 1 つの CLK ピン) を使用するだけです。 SPI ポートの選択入力ピンと出力ピンは、マスター モードとスレーブ モードの両方とマルチマスター環境をサポートする全二重 SSI (同期シリアル インターフェイス) を提供します。この SPI ポートのボーレートとクロック位相または極性はプログラム可能です。このポートには、データ ストリームの送受信をサポートする DMA コントローラが組み込まれています。
タイマー
Blackfin プロセッサには、9 つのプログラマブル タイマー ユニットがあります。これらのタイマーは、プロセッサのクロックまたは外部信号カウントへの同期を目的とした定期的なイベントを提供するために、プロセッサ コアへの割り込みを生成します。
UART
UART という用語は、「ユニバーサル非同期受信機送信機」ポートを表します。 Blackfin プロセッサは、2 つの半二重 UART ポートを提供します。これらは、PC 標準 UART に完全に適合しています。これらのポートは、他のホストまたはペリフェラルに基本的な UART インターフェイスを提供するだけで、DMA 対応の半二重非同期シリアル データ転送を提供します。
UART ポートには 5 ~ 8 個のデータ ビットと 1 ~ 2 個のストップ ビットが含まれており、プログラムされた I/O と DMA のような 2 つの動作モードをサポートしています。最初のモードでは、プロセッサは、データが送信と受信の両方で 2 回バッファリングされる場合に、I/O マップ レジスタの読み取り/書き込みを通じてデータを送信または受信します。 2 番目のモードでは、DMA コントローラはデータを送受信し、データをメモリからメモリに送信するために必要な割り込みの数を減らします。
RTC またはリアルタイムクロック
blackfin プロセッサのリアルタイム クロックは、ストップウォッチ、現在時刻、アラームなどのさまざまな機能を提供します。そのため、リアルタイム クロックは、Blackfin プロセッサの外部にある 32.768 kHz 水晶でクロックされます。プロセッサ内のRTCには電源ピンがあり、Blackfinプロセッサの残りの部分が低電力状態になった後でも、電源を入れたままにしておくことができます。リアルタイム クロックは、多数のプログラム可能な割り込みオプションを提供します。 32.768 kHz の入力 CLK 周波数は、プリスケーラーによって 1 Hz の信号に分離されます。他のデバイスと同様に、リアルタイム クロックは Blackfin プロセッサをディープ スリープ モード/スリープ モードから復帰させることができます。
ウォッチドッグタイマー
Blackfin プロセッサには、ソフトウェア ウォッチドッグ機能の実行に使用される 32 ビット ウォッチドッグ タイマーがあります。そのため、プログラマは適切な割り込みを許可するタイマーのカウント値を初期化し、次にタイマーを許可します。その後、プログラムされた値から「0」にカウントする前に、ソフトウェアはカウンタをリロードする必要があります。
GPIO または汎用 I/O
GPIO は、入力、出力、またはその両方として使用され、ソフトウェアによって制御されるデジタル信号ピンです。 Blackfin プロセッサには、ポート G、ポート H、ポート F にそれぞれ接続された PORTFIO、PORTHIO、PORTGIO などの 3 つの独立した GPIO モジュール全体で 48 の双方向の GPIO (汎用 I/O) ピンが含まれています。すべての汎用ポート ピンは、GPIO DCR、GPIO CSR、GPIO IMR、GPIO ISR などのステータス、ポート制御、および割り込みレジスタの操作によって個別に制御されます。
イーサネット MAC
Blackfin プロセッサのイーサネット MAC ペリフェラルは、MII (Media Independent Interface) と Blackfin のペリフェラル サブシステムの間で 10 ~ 100 Mb/s を提供します。 MAC は、全二重モードと半二重モードの両方で機能します。メディア アクセス コントローラは、プロセッサの CLKIN ピンから内部的にクロック供給されます。
メモリー
Blackfin プロセッサ アーキテクチャのメモリは、デバイスの実装でレベル 1 とレベル 2 の両方のメモリ ブロックを提供するだけです。データおよび命令メモリのような L1 のメモリは、プロセッサ コアに直接接続されるだけで、完全なシステム CLK 速度で動作し、クリティカル タイム アルゴリズム セグメントに対して最大のシステム パフォーマンスを提供します。 SRAM メモリのような L2 メモリはサイズが大きいため、パフォーマンスが少し低下しますが、オフチップ メモリと比較すると、それでも高速です。
L1 メモリの構造は、マイクロコントローラでプログラムを提供しながら、信号処理に必要なパフォーマンスを提供するために実装されています。これは、メモリ L1 を SRAM、キャッシュ、または両方の組み合わせとして配置できるようにするだけで実現できます。
キャッシュおよび SRAM プログラミング モデルをサポートすることにより、システムの設計者は、キャッシュ メモリ内にリアルタイム制御または OS タスクを格納しながら、低レイテンシと高帯域幅を必要とする重要なリアルタイム信号処理データ セットを SRAM に割り当てます。
起動モード
Blackfin プロセッサには、リセット後に内部 L1 命令メモリを自動的にロードするための 6 つのメカニズムが含まれています。したがって、さまざまなブートモードには主に次のものが含まれます。 8 ビット & 16 ビットの外部フラッシュ メモリ、シリアル SPI メモリからのブート モード。 SPI ホスト デバイス、UART、シリアル TWI メモリ、TWI ホストは、ブート シリーズをバイパスして、16 ビット外部メモリから実行します。最初の 6 つのブート モードのそれぞれで、最初に 10 バイトのヘッダーが外部メモリ デバイスから読み取られます。したがって、ヘッダーはいいえを示します。送信するバイト数とメモリ宛先アドレス。いくつかのメモリ ブロックは、どのブート シリーズでもロードできます。すべてのブロックが単純にロードされると、プログラムの実行は L1 命令 SRAM の先頭から開始されます。
アドレッシング モード
blackfin プロセッサのアドレッシング モードは、個々のアクセス メモリとアドレッシングがロケーションを指定する方法を決定するだけです。 blackfin プロセッサで使用されるアドレッシング モードは、間接アドレッシング、自動インクリメント/デクリメント、ポスト モディファイ、イミディエート オフセットによるインデックス付け、循環バッファ、およびビット リバースです。
間接アドレッシング
このモードでは、命令内のアドレス フィールドには、効率的なオペランドのアドレスが存在するメモリまたはレジスタの場所が含まれます。このアドレッシングは、レジスタ間接とメモリ間接の 2 つのカテゴリに分類されます。
たとえば、LOAD R1、@300
上記の命令では、実効アドレスは単純にメモリ位置 300 に格納されます。
自動インクリメント/デクリメント アドレッシング
自動インクリメント アドレッシングは、エントリの直後にポインタ レジスタとインデックス レジスタを更新するだけです。インクリメントの量は、主にワード サイズのサイズに依存します。 32 ビット ワード アクセスは、「4」によるポインタ更新内で発生する可能性があります。 16 ビット ワード アクセスはポインタを「2」で更新し、8 ビット ワード アクセスはポインタを「1」で更新します。 8 ビットと 16 ビットの両方の読み取り操作は、内容をターゲット レジスタにゼロ拡張/符号拡張することを示す場合があります。ポインタ レジスタは主に 8、16、および 32 ビット アクセスに使用されますが、インデックス レジスタは 16 および 32 ビット アクセスのみに使用されます。
“光センサーとは ”
例: R0 = W [ P1++ ] (Z) ;
上記の命令では、ポインタ レジスタ「P1」を介して、16 ビット ワードがポイントされたアドレスから 32 ビット デスティネーション レジスタにロードされます。その後、ポインタが 2 増加し、ワードが「0」に拡張されて 32 ビットのデスティネーション レジスタがいっぱいになります。
同様に、自動デクリメントは、エントリの右の後のアドレスを減少させることによって機能します。
例: R0 = [ I2– ] ;
上記の命令では、32 ビット値がデスティネーション レジスタにロードされ、インデックス レジスタが 4 減ります。
変更後のアドレッシング
このタイプのアドレッシングは、効率的なアドレスのようにインデックス/ポインタ レジスタ内の値を使用するだけです。その後、レジスタ内容で修正します。インデックス レジスタは変更されたレジスタで単純に変更されますが、ポインタ レジスタは他のポインタ レジスタで変更されます。デスティネーション レジスタと同様に、Post-modify タイプのアドレッシングは Pointer レジスタをサポートしていません。
例: R3 = [ P1++P2 ] ;
上記の命令では、32 ビット値が「R3」レジスタにロードされ、「P1」レジスタが指すメモリの場所内で検出されます。その後、「P2」レジスタ内の値が P1 レジスタ内の値に加算されます。
即時オフセットで索引付け
インデックス付きアドレッシングは、プログラムがデータ テーブルから値を取得できるようにするだけです。 Pointer レジスタは即値フィールドによって変更され、その後は実効アドレスとして使用されます。そのため、ポインタ レジスタの値は更新されません。
たとえば、P1 = 0x13 の場合、[P1 + 0x11] は効率的に [0x24] に相当し、すべてのアクセスに関連付けられます。
ビット逆アドレッシング
一部のアルゴリズムでは、プログラムは、特に FFT (高速フーリエ変換) 計算の場合、結果を順番に取得するためにビット反転キャリー アドレス指定を必要とします。これらのアルゴリズムの要件を満たすために、データ アドレス ジェネレーターのビット反転アドレッシング機能を使用すると、データ系列を細分化し、このデータをビット反転順に格納できます。
循環バッファーのアドレス指定
Blackfin プロセッサは、オプションの循環アドレッシングのような機能を提供します。これは、事前定義されたアドレス範囲だけインデックス レジスタを単純に増やした後、インデックス レジスタを自動的にリセットしてその範囲を繰り返します。したがって、この機能は、アドレス インデックス ポインターを毎回削除するだけで、入出力ループのパフォーマンスを向上させます。
循環バッファ アドレス指定は、固定サイズのデータ ブロックの文字列を繰り返しロードまたは格納する場合に非常に便利です。循環バッファーの内容は、次の条件を満たす必要があります。
- 循環バッファーの最大長は、大きさが 231 未満の符号なしの数値である必要があります。
- 修飾子の大きさは、循環バッファーの長さより小さくなければなりません。
- ポインター「I」の最初の位置は、長さ「L」と基数「B」によって定義される循環バッファー内にある必要があります。
上記の条件のいずれかが満たされない場合、プロセッサの動作は指定されません。
Blackfin プロセッサのレジスタ ファイル
Blackfin プロセッサには、次のような 3 つの決定的なレジスタ ファイルが含まれています。データ レジスタ ファイル、ポインタ レジスタ ファイル、および DAG レジスタ。
- データ レジスタ ファイルは、計算ユニットに使用されるデータ バスを使用してオペランドを収集し、計算結果を格納します。
- ポインタ レジスタ ファイルには、アドレッシング操作に使用されるポインタが含まれています。
- DAG レジスタは、DSP 操作に使用されるゼロ オーバーヘッドの循環バッファを管理します。
Blackfin プロセッサは、最高の電力管理とパフォーマンスを提供します。これらは、電圧と動作周波数の両方を変更して全体的な電力使用率を大幅に削減できる低電圧および低電力設計手法で設計されています。そのため、動作周波数を変更するだけの場合と比較して、電力使用率が大幅に低下する可能性があります。したがって、これにより、便利な電化製品のバッテリー寿命が長くなります。
Blackfin プロセッサは、DDR-SDRAM、SDRAM、NAND フラッシュ、SRAM、NOR フラッシュなどのさまざまな外部メモリをサポートしています。一部の Blackfin プロセッサは、SD/SDIO や ATAPI などの大容量ストレージ インターフェイスも備えています。また、外部メモリのスペース内で 100 メガバイトのメモリをサポートできます。
利点
の Blackfin プロセッサの利点 以下のものが含まれます。
- Blackfin プロセッサは、システムの設計者に基本的な利点を提供します。
- Blackfin プロセッサは、マルチフォーマットでのオーディオ、ビデオ、音声および画像処理、リアルタイム セキュリティ、制御処理、マルチモード ベースバンド パケット処理などの収束アプリケーションに、ソフトウェアの柔軟性とスケーラビリティを提供します。
- 効率的な制御処理能力と高性能信号処理により、さまざまな新しい市場とアプリケーションが可能になります。
- DPM (Dynamic Power Management) により、システム設計者はデバイスの消費電力をエンド システムの要件に合わせて特に変更できます。
- これらのプロセッサは、開発時間とコストを大幅に削減します。
アプリケーション
の Blackfin プロセッサのアプリケーション 以下のものが含まれます。
- Blackfin プロセッサは、次のような多くのアプリケーションに最適です。 ADAS(自動車用先進運転支援システム) 、監視またはセキュリティ システム、産業用マシン ビジョン。
- Blackfin アプリケーションには、サーボ モーター制御システム、自動車用電子機器、監視システム、マルチメディア コンシューマ デバイスが含まれます。
- これらのプロセッサは、マイクロコントローラと信号処理機能を実行するだけです。
- これらは、オーディオ、プロセス制御、自動車、テスト、測定などに使用されます。
- Blackfin プロセッサは、ブロードバンド ワイヤレス、モバイル通信、オーディオまたはビデオ対応のインターネット アプライアンスなどの信号処理アプリケーションで使用されます。
- Blackfin は、ネットワークおよびストリーミング メディア、デジタル ホーム エンターテイメント、自動車テレマティクス、インフォテインメント、モバイル TV、デジタル ラジオなどの統合アプリケーションで使用されます。
- Blackfin プロセッサは、マルチフォーマットの音声、オーディオ、ビデオ、マルチモード ベースバンド、画像処理、パケット処理、リアルタイム セキュリティおよび制御処理が重要なアプリケーションで使用される電力効率と最高のパフォーマンスを備えた組み込みプロセッサです。
したがって、これは Blackfin プロセッサの概要 – アーキテクチャ、利点、およびそのアプリケーション。このプロセッサは、信号処理とマイクロコントローラ機能を実行します。ここであなたに質問があります。プロセッサーとは何ですか?