
ソファに座ってリラックスして、コンピューター、ラップトップ、または携帯電話に、文字の入力やいくつかのコマンドの実行などの簡単なタスクを実行するように指示することを想像してみてください。出来ますか?
もちろん、それが音声認識の出番です。
定義によれば、それは人間の音声を認識し、それをテキスト形式にデコードするプロセスです。
原理
の基本原則 音声認識 人間が話すスピーチや言葉が、音波として知られる空気の振動を引き起こすという事実が関係しています。これらの連続波またはアナログ波は、デジタル化および処理されてから、適切な単語、次に適切な文にデコードされます。

音声認識システムのコンポーネント
では、基本的な音声認識システムは何で構成されていますか?

- 音声キャプチャデバイス :音波信号を電気信号に変換するマイクと、アナログ信号をサンプリングしてデジタル化し、コンピューターが理解できる離散データを取得するアナログ-デジタルコンバーターで構成されています。
- デジタル信号モジュールまたはプロセッサ :周波数領域変換などの生の音声信号の処理を実行し、必要な情報のみを復元します。
- 前処理された信号ストレージ :前処理された音声はメモリに保存され、音声認識のさらなるタスクを実行します。
- 参照音声パターン :コンピュータまたはシステムは、マッチングの参照として使用される、メモリにすでに保存されている事前定義された音声パターンまたはテンプレートで構成されています。
- パターンマッチングアルゴリズム :未知の音声信号を参照音声パターンと比較して、実際の単語または単語のパターンを決定します。
システムの動作
次に、システム全体が実際にどのように機能するかを見てみましょう。

- スピーチは、音響波形、つまりメッセージ情報を運ぶ信号として見ることができます。調音器(音声器官)の動きの速度が制限されている通常の人間は、1秒あたり平均10音の速度で音声を生成できます。平均情報レートは約50〜60ビット/秒です。これは、実際には音声信号に必要な情報は50ビット/秒のみであることを意味します。この音響波形は、マイクによってアナログ電気信号に変換されます。アナログ-デジタルコンバーターは、離散的な間隔で波を正確に測定することにより、このアナログ信号をデジタルサンプルに変換します。
- デジタル化された信号は、1秒間に16000回サンプリングされた周期的な信号のストリームで構成されており、実際の実行には適していません。 音声認識 パターンを簡単に見つけることができないため、プロセス。実際の情報を抽出するために、時間領域の信号が周波数領域の信号に変換されます。これは、FFT技術を使用してデジタルシグナルプロセッサによって行われます。デジタル信号では、1/100ごとのコンポーネントth1秒の時間が分析され、そのような各コンポーネントの周波数スペクトルが計算されます。言い換えれば、デジタル化された信号は周波数振幅の小さな部分に分割されます。
- 各セグメントまたは周波数グラフは、人間が発するさまざまな音を表しています。コンピュータは、未知のセグメントと特定の言語の保存された音声学とのマッチングを実行します。このパターンマッチングは、次の3つの方法で行われます。
音響音声アプローチの使用 :音響音声アプローチでは、通常、隠れマルコフモデルが使用されます。このモデルは、音声認識のための非決定論的確率モデルを開発します。このモデルは、コンピュータメモリに保存されている音素の隠れた状態とデジタル信号の可視周波数セグメントの2つの変数で構成されています。各音素には独自の確率があり、セグメントは確率に従って音素と照合され、一致した音素が一緒に収集されて、言語の保存された文法規則に従って正しい単語が形成されます。
パターン認識アプローチの使用 :パターン認識アプローチでは、システムは任意の言語の特定の音声パターンでトレーニングされ、タイムワーピング技術を使用して信号間の距離を決定することにより、未知の音声パターンが参照音声パターンと比較されます。
人工知能の使用 :人工知能のアプローチは、スペクトル測定に基づいて話される音の知識、適切な意味のある構文上の単語の知識などの基本的な知識源の利用に基づいています。
音声認識システムが依存する要因
音声認識システムは、次の要因に依存します。
- 孤立した言葉 :連続する単語は重複する可能性があり、システムが単語の開始または終了を理解するのが困難になる可能性があるため、話される連続する単語の間に一時停止が必要です。したがって、連続する単語の間に沈黙が必要です。
- シングルスピーカー :同時に音声入力を行おうとする多くのスピーカーは、信号のオーバーラップや中断を引き起こす可能性があります。使用される音声認識システムのほとんどは、話者に依存するシステムです。
- 語彙サイズ :語彙が多い言語は、語彙が少ない言語よりもパターンマッチングを考慮するのが困難です。後者の方が、単語があいまいになる可能性が低いためです。
Windows7の音声認識システム
音声認識システムにWindows7を使用している人には、次の手順をお勧めします
- スタートメニューから、またはアイコンをクリックして、コントロールパネルを開きます。
- [コンピューターの簡単操作]を選択し、[音声認識]をクリックします。
- 次に、[マイクの設定]をクリックし、使用可能なオプションからデスクトップマイクを選択します。
- 次に、スピーチチュートリアルを受講し、指定された指示に従います。
- その後、コンピュータが音声信号の明確なパターンを保存するように、より良いオプションのためにコンピュータをトレーニングします。これを行うには、[コンピュータをトレーニングして理解を深める]オプションをクリックし、指示に従います。
- 次に、音声認識アイコンを開始し、コンピューターに音声を口述し始めます。コンピュータ辞書に自分の単語を追加することもできます。
実用的な音声認識システム:HM2007の使用
音声認識ICを用いて実用的な音声認識システムを構築できる HM2007 。 HM2007は音声認識機能を備えた48ピンICです。手動モードまたはCPUモードの2つのモードで動作します。どちらのモードでも、ICは最初に、キーで押された対応する番号の各単語をユーザーが言うことによって単語を認識するようにトレーニングされます。 ICは、各ワード信号をワードに対応するメモリ位置に格納します。 ICから出力されたデータはマイクロコントローラーに接続され、そこからLCDに表示されます。

通常、HM2007の操作には手動モードを使用します。
- HM2007は、ICがトレーニング目的の準備ができていることを示すアクティブローピンであるRDYピンで構成されています。
- 音声入力は、ICのMICINピンに接続されたマイクを介して行われます。
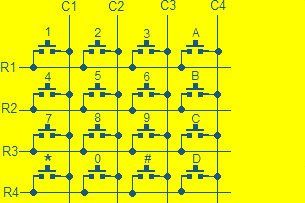
- ICは、各単語に対応する数字入力を提供するために使用されるキーパッドとインターフェースします。 ICは、クリアとトレインの2つの機能で動作します。キーボードのトレーニングキーが押されると、ICはトレーニングプロセスを開始します。
- ユーザーは、「トレーニング」ファンクションキーを押す前に数字キーを押して、マイクに必要な単語を言います。
- ICは、SRAMの対応するMEピンに接続されているME(メモリイネーブル)ピンにHigh信号を送信します。押された数に対応する8ビットのデータ信号は、外部バスを介してSRAM(外部RAM)に格納されます。
- 音声入力が検出された後、RDYピンはロジックハイになり、ICは認識状態になり、認識プロセスを開始します。
- プロセスの結果は、DEN(データイネーブル)ピンがハイのデータバスを介して提供されます。
- 次に、8ビットデータを直列インターフェイスプロセッサを介してマイクロコントローラに渡すか、ラッチIC74HC573を使用して最初にラッチすることができます。
- マイクロコントローラはLCDと接続されており、対応する単語がディスプレイに表示されるようにプログラムされています。
取るべき唯一の予防策は、同音異義語(同じような音の単語)を使用しないことと、声の興奮に注意を払うことです。
だから、これはすべての方法です 基本的な音声認識システム 動作します。さらに入力を追加することを歓迎します。
画像クレジット
音声認識および話者認識の概要による音声認識システムのコンポーネント– Richard D.PeacockeおよびDarylH。Graf






{kind=link}